Recently, the Peking University Laboratory for Future Networks, a national major science and technology infrastructure, has achieved a series of important research outcomes in software engineering and large language model(LLM)-basedsecuritycodegeneration. Two research papers completed under the guidance of Professor Hui Li and with the participation of PhD student Bin Wang have been accepted by ICSE 2026, a top international conference in the field of software engineering. The two papers are titled“Argus: A Multi-Agent Sensitive Information Leakage Detection Framework Based on Hierarchical Reference Relationships”and“Attention Distance: A Novel Metric for Directed Fuzzing with Large Language Models.”
ICSE(the IEEE/ACM International Conference on Software Engineering)is widely recognized as one of the premier academic conferences in the international software engineering community and has long been regarded as the flagship conference with the greatest influence in the field. The conference brings together cutting-edge research achievements from leading universities, research institutions, and major technology companies around the world, and maintains exceptionally high standards for innovation, rigor, and practical value. The simultaneous acceptance of two papers by ICSE fully demonstrates the laboratory’s sustained capacity for innovation and its international academic competitiveness in areas such as intelligent software engineering, security analysis, and large language model-empowered software engineering.

Figure 1.Excerpt from the official homepage of the IEEE/ACM International Conference on Software Engineering。

Figure 2.Team members delivering an on-site presentation at the conference。
The paper“Argus: A Multi-Agent Sensitive Information Leakage Detection Framework Based on Hierarchical Reference Relationships”focuses on the challenging problem of detecting sensitive information leakage in open-source code repositories. Traditional detection methods based on regular expression rules, fingerprint features, and information entropy often suffer from high false-positive rates and require substantial manual review. To address these issues, the research team proposedArgus, a collaborative multi-agent detection framework. The method conducts joint analysis at three levels: the sensitive information content itself, file-level contextual semantics, and project-level reference relationships. Through task division and collaboration among multiple agents, Argus effectively improves the identification of real leaks while significantly reducing the proportion of false positives. The paper alsointroducestwo new benchmark datasets for real-world repository scenarios, which are used to evaluate leakage detection capability and false-positive filtering capability, respectively. Experimental results demonstrate strong engineering practicality and potential for real-world deployment.
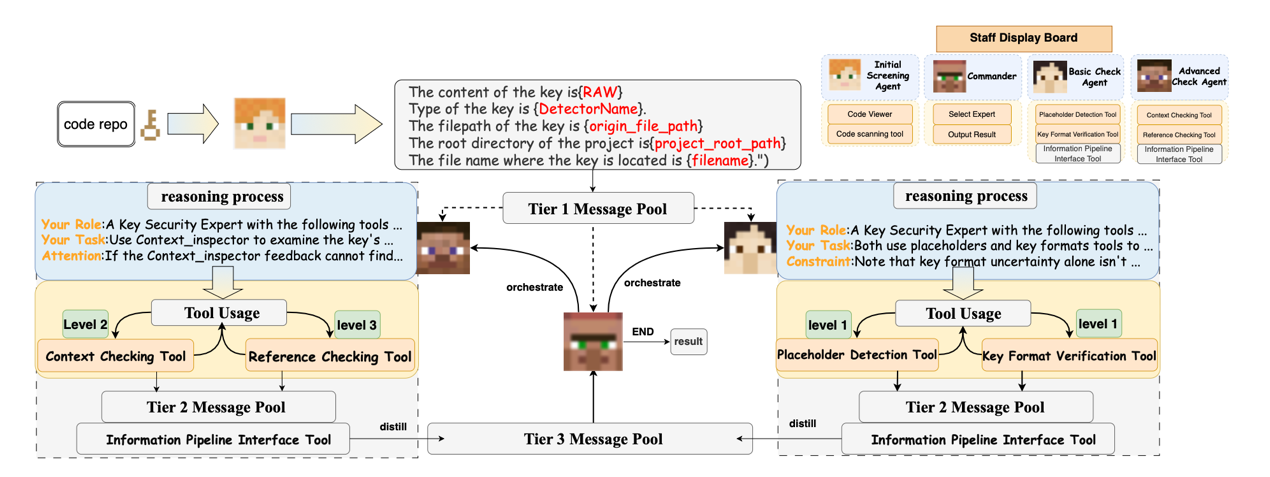
Figure 3. Schematicdiagram of the Argus framework。
The paper“Attention Distance: A Novel Metric for Directed Fuzzing with Large Language Models”investigates directed grey-box fuzzing in software security testing. Most existing directed fuzzing methods rely on “physical distance” in program structure to assess how close an input is to the target vulnerability location. However, such methods often overlook the actual logical dependencies among code paths, which can lead to misleading path guidance in complex programs and reduce the efficiency of vulnerability triggering. To overcome this bottleneck, the research team proposed a new distance metric calledAttention Distance. This metric introduces the capability of large language models to understand semantic relationships in code into directed fuzzing. By assigning context-aware attention scores to code statements, it generates more discriminative path-guidance signals. Experimental results show that, without changing any other components of AFLGo and only replacing the distance metric, the proposed method improves testing efficiency by an average of3.43×across 38 real-world vulnerability reproduction experiments. Compared with advanced directed fuzzing tools DAFL and WindRanger, it achieves performance improvements of2.89×and7.13×, respectively, demonstrating the broad potential of large model-based semantic analysis in empowering software security testing.
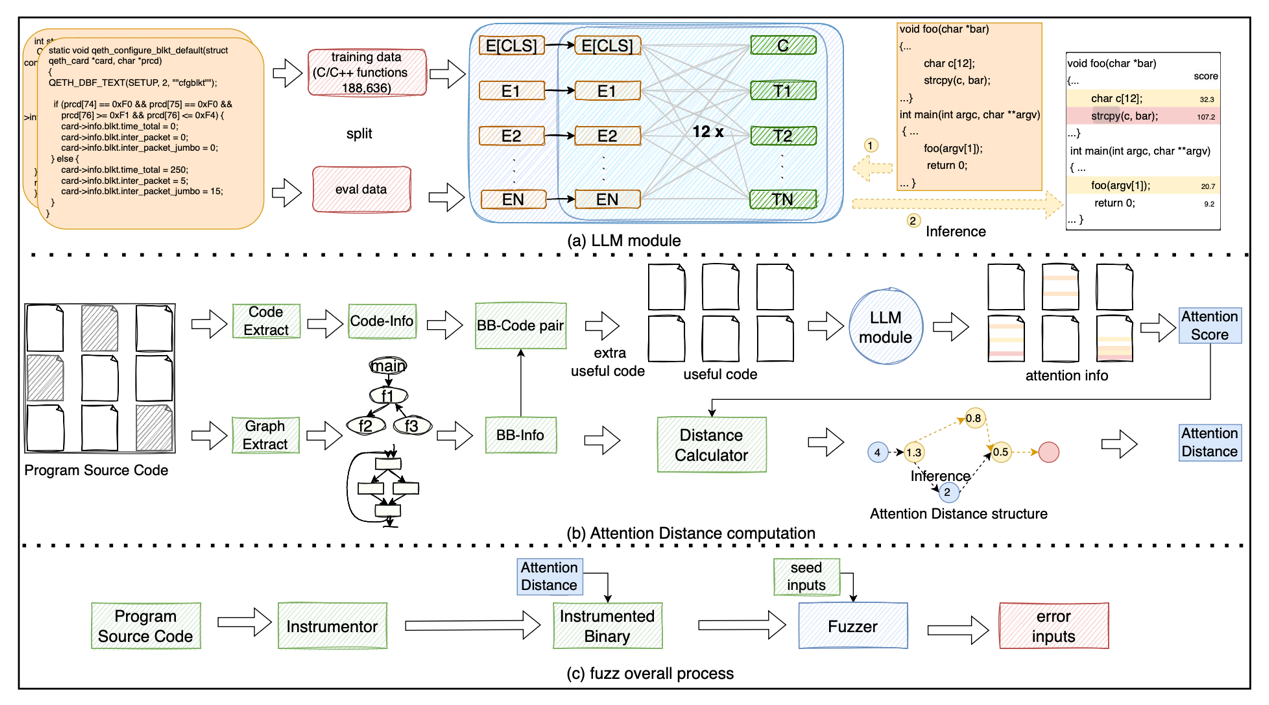
Figure 4. Attention Distance framework diagram
In addition, over the past two years, the team has published multiple papers related to LLMs and code security at leading AI conferences, including a paper atAAAIon a standardized agent module-augmented code-generation framework for secure code generation,ICMLon improving code security through reinforcement learning, andACLon repository-level secure code generation. The team has also published inEmpirical Software Engineering, an influential journal in the software engineering field, with an empirical analysis of the impact of flawed prompts on secure code generation.
Beyond high-level academic publications, the laboratory has also continued to advance the development of open-source platforms for LLM-based code security and AI system security. In collaboration with Tencent, the laboratory has released two representative achievements. The first isA.S.E., orAICGSecEval, a benchmark and evaluation framework for project-level and repository-level security assessment of AI-generated code. By simulating real-world software development workflows, A.S.E. aims to systematically evaluate the security of generated code in AI-assisted programming scenarios. Publicly available information indicates that the framework focuses on code security evaluation in real engineering contexts, covering multiple mainstream programming languages and various common types of security risks. It provides a repository-level evaluation foundation that is closer to real-world software development scenarios for research on AI-generated code security. Since its release, A.S.E. has attracted broad attention. It ranked first on Hugging Face’s“Paper of the Day”list and topped the weekly ranking in Week 36 of 2025, reflecting strong trend-setting influence and community recognition.
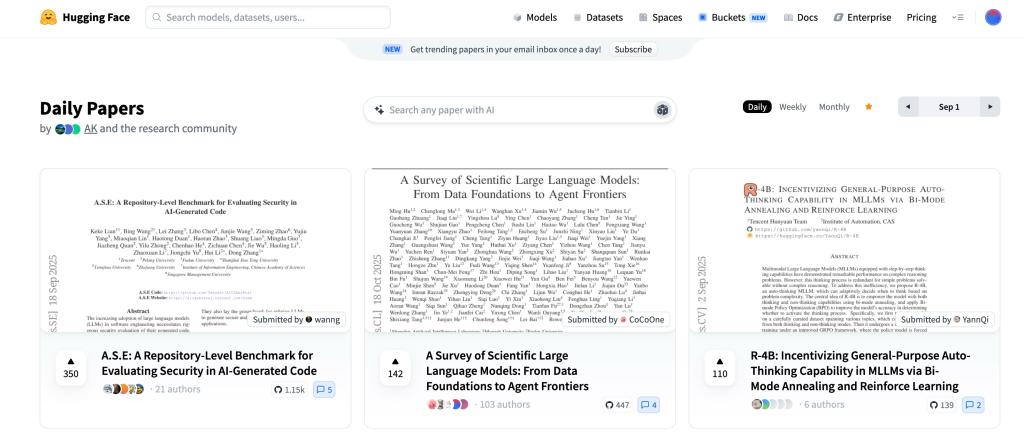
Figure 5.Hugging Face “Paper of the Day” and weekly ranking
The second achievement,A.I.G., orAI-Infra-Guard, is a full-stack AI red-teaming platform for AI ecosystem security. The platform integrates capabilities such as OpenClaw security detection, Agent Scan, MCP scanning, AI infrastructure vulnerability scanning, and model jailbreak evaluation. It covers security analysis needs ranging from agent workflows to underlying infrastructure, reflecting the laboratory’s systematic exploration of AI system security, toolchain development, and automated security evaluation in complex scenarios. Public information shows that A.I.G. has developed a relatively comprehensive platform capability framework, providing strong security assessment support for AI applications, agent systems, and related development ecosystems. Both A.S.E. and A.I.G. have achieved broad influence in the open-source community, each receiving more than one thousand stars on GitHub.

Figure 6.Excerpt from the GitHub homepage of the A.I.G. project。
In terms of theoretical synthesis and knowledge system development, the laboratory has published the academic monograph《大语言模型与安全代码生成》by Tsinghua Univ.and its English edition,Large Language Models and Secure Code Generation. Against the backdrop of the rapid evolution of large language models and the widespread adoption of AI-assisted programming, the books provide a systematic overview of the core principles of code generation, security enhancement methods, evaluation systems, and future development trends. Starting from the development trajectory of large language models and the semantic modeling principles of Transformers, the works further examine code-oriented large language models, technologies related to LLM security enhancement, security enhancement methods for code generation, the evaluation and practice of code generation models, and the intrinsic integration of paradigm shifts in artificial intelligence with cyberspace security. Together, these contents form a relatively comprehensive knowledge framework and reflect the laboratory’s long-term accumulation and systematic thinking in large language model-based code generation and security enhancement.

Figure 7.Cover of the team’s English monograph。
Looking ahead, the laboratory will continue to conduct in-depth research on the foundational theories of software engineering in the era of large language models, intelligent security evaluation methods, and secure and trustworthy code generation systems. It will further promote the translation of research outcomes into both academic impact and industrial applications.


